

딥러닝
[2019-1]
# 01
일단은 용어정리를 하였다.
인공지능은 시스템을 통해 컴퓨터가 인간과 유사한 사고 구조를 구현할 것을 말한다.
머신러닝은 기계를 학습시켜 인간보다 정확하고 올바른 결과를 도출하게 하는 방법이며, 사람이 필요한 데이터를 넣어서 학습시켜야 한다.
딥러닝은 머신러닝과 유사하나 사람이 데이터를 선정하여 학습시킬 필요 없이, 에이전트(학습하는 기계..?, 프로그램 주체)스스로가 필요한 특성을 찾아나가는 것이다.
즉, 집합으로 따지면, 인공지능⊃머신너링⊃딥러닝이다.
딥러닝 앞부분은 머신러닝과 비슷하므로, 그냥 혼용해서 쓰겠다.
인공 신경망 학습을 위한 신경망은 머신러닝의 가장 작은 단위이다. 예를 들어, 집 크기를 예측한다고 할 때, x라는 크기가 주어지면 y라는 가격을 도출해 내는 일을 하는 가장 작은 단위가 신경망인 것이다.
여기서 x라는 크기가 주어지고, y라는 가격을 도출해 내는 과정에서 쓰이는 함수가 있을 것인데, 딥러닝을 통해서 함수를 구한다.
값이 주어져 있을 때의 함수는 선형 회귀 방법을 쓰는데, 밑의 그림 중에 ReLu(Rectified Linear unit)함수가 선형 회귀 분석을 통해서 얻은 함수이다.
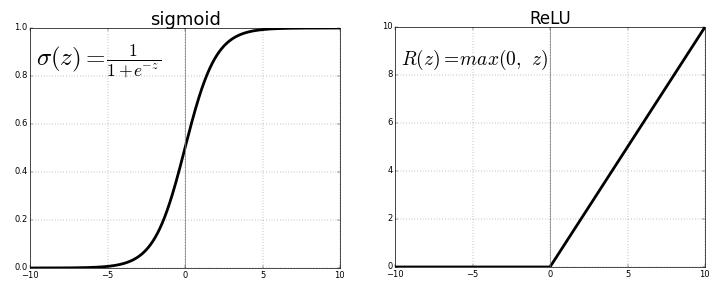
시그모이드도 나중에 이야기할 것인데, 어쨌든 이렇게 신경망이 주어진 x에 대해 결과값 y를 도출해낸다.
신경망이 복잡해지면, 여러 xi들에 대해 결과값들을 도출해 낼텐데, 그 사이에 거치는 과정들이 늘어날 수 있고, 그런 노드를 hidden layer라고 한다.
만약 xi가 데이터와 관계 없어도 신경망이 스스로 걸러주고, 이 점이 머신러닝과 딥러닝의 차이점이다.
데이터에는 구조적 데이터와 비구조적 데이터가 있는데, MySQL과 같은 관계형 DB에 들어갈 수 있는 row와 column이 존재하는 데이터들을 구조적 데이터라고 한다. 반대로 비구고적 데이터는 음성이나 자연어, 사진등이 있는데 이들을 구조적 데이터로 변환하여 분석하곤 한다.
머신너링 학습에는 지도학습(supervised learning)과 비지도 학습(non-supervised learning), 강화 학습(reinforcement learning)이 있다.
지도 학습은 데이터에 대한 레이블(명시적인 답, (xi, yi)로 표기함)이 주어진 상태에서 학습시키는 것을 말하며, 비지도 학습은 데이터를 비슷한 특성끼리 분류하는 클러스터링 알고리즘 등이다. 비지도 학습을 통해 숨겨진 특성이나 구조를 알아낼 수 있다. 강화 학습은 에이전트가 주어진 환경에서 행동을 하고 reward를 얻으며 학습을 진행하는 것이다. reward는 그냥 에이전트가 잘하면 포인트를 올리는 식으로..한다고 한다.
예전에는 데이터가 별로 없어서 성능 비교가 불가능했고, 신경망 설계에 드는 비용이 더 커서 딥러닝이 발전하지 못했다.
하지만 밑의 그림과 같이, 알고리즘과 딥러닝은 성능에 있어서 차이가 크다.
결과적으로 딥러닝 성능결과는 데이터양과 신경망 규모에 비례하는 것이다.

딥러닝이 이제서야 발전한 이유는 데이터의 양이 향상되었고, CPU가 GPU로 교체되어 병렬처리가 쉬워지면서 연산 수행 속도가 빨라졌기 때문이다. 그리고 알고리즘 개선도 한 몫했는데, 그건 바로 밑에서 설명하겠다.
딥러닝 프로젝트는 크게 idea와 code, experiment로 이루어진다. idea 과정에서는 알고리즘을 어떻게 짜야할 것인지에 대해 고민하고, code 과정에서 신중히 코딩을 한다. 실수를 최대한 줄여야 하는데, experiment 과정에서 한 번 코드를 돌려보는데 거의 한나절이 걸리기 때문이다. 따라서 딥러닝 experiment 과정 시간을 줄이기 위해서 알고리즘이 개선되고 있다. 알고리즘이 개선되어 시간이 빨라지고, 계산 속도가 빨라진 것인데, ReLu함수와 Sigmoid함수가 그 예이다. Sigmoid 함수는 경사하강법에 불리하고, ReLu함수는 경사하강법에 유리하다는 특징이 있는데, 경사하강법에 대한 이야기를 하려면 이진 분류과 로지스틱 회귀 이야기를 먼저 해야 한다.
머신 러닝에서 사진을 보고 0과 1로 결과값을 산출해야 하는 경우가 있다. 무언가를 판단할 때가 그러한데, 대표적으로 고양이 사진을 보고 고양이인지 아닌지 판별할 때 이진 분류를 수행해야 한다.
훈련 샘플이 (x1, y1), (x2, y2) ... (xm, ym)로 m쌍이 있다면 훈련 샘플의 크기를 m이라고 한다.
여기서 x는 물론 input이고 y는 output이다.
x는 특징 벡터로 이루어 지는데, 훈련 샘플의 크기가 m개니까 x=[x1 x2 x3 ... xm] 형태로 쓸 수 있다.
일반적으로 x=
이러면 x.shape(nx, m)이라고 쓰고, 여기에 대응하는 y.shape(1,m)가 된다. 왜냐하면 y는 0과 1 중에 하나이기 때문에 차원이 1이기 때문이다.
차원이라는 것은 nx로 y에 대응 되는 x의 훈련샘플의 종류의 개수이다. 쉽게 말하자면, 특성의 종류가 몇 개인지를 나타내는 것이다. 만약 y를 결정하는데, x의 특성이 4개가 필요하다면 x의 차원은 4인 것이고, nx=4라고 표현한다.
다시 로지스틱 회귀로 돌아오면, 로지스틱 회귀는 물론 회귀분석의 방법 중 하나이다. 정의는 확률 모델로서 독립 변수의 선형 결합을 이용해 사건의 발생 가능성을 예측하는 데에 사용되는 통계 기법인데, 즉, 로지스틱을 쓰는 이유는 사건의 발생 가능성을 예측하려고 사용하는 것이다.
로지스틱은 지도학습(훈련 샘플이 주어졌을 때)에서 레이블(결과값y)이 1아니면 0일 때(이진 분류) 쓰인다.
따라서 그래프가가 시그모이드 함수의 형태를 하게 된다.
수식을 입력해야 하는데, 귀찮다..
그냥 말로 하자면, 시그모이드 함수를 o라고 하면, y=o(z), z=wx+b, 0<=y<=1라고 쓸 수 있다. 시그모이드 함수 안에 선형회귀식을 넣은 것임.
시그모이드 함수는 (1+e^(-z))^(-1)인데(위의 그래프에 식 있음), 이 식에서는 z가 무한대로 가면 o(z)는 1로가고, z가 음의 무한으로 가면 o(z)가 0으로 간다.
로지스틱을 선형과 비교해서 설명하자면,,,수식을 써야 하네..........수식 입력이 귀찮은데..
어쨌든 선형 회귀식과 로지스틱 회귀식은 다른 형태를 띈다.
w와 b를 찾는 최종 목표를 달성하기 위해서 최적화 값을 찾으려면 최소값이 하나인 것이 좋은데, 비용함수가 그 역할을 한다.
그래서 비용함수를 로지스틱으로 구한다는 건가? 나중에 물어봐야 겠다.
일단 여기까지.
'EVI$I0N > 2019-1' 카테고리의 다른 글
| [디지털포렌식] #02 (0) | 2019.04.06 |
|---|---|
| [웹보안] #02 (0) | 2019.04.01 |
| [와이어샤크] #01 (0) | 2019.03.25 |
| [디지털포렌식] #01 (0) | 2019.03.23 |
| [웹보안] #01 (0) | 2019.03.16 |